


🐏🐕🐁🦌 学习网络的 3D 动物群

抽象的
学习地球上所有动物的 3D 模型需要大规模扩展现有解决方案。考虑到这一最终目标,我们开发了3D-Fauna,这是一种联合学习 100 多种动物物种的泛类别可变形 3D 动物模型的方法。动物建模的一个关键瓶颈是训练数据的可用性有限,我们通过简单地从 2D 互联网图像中学习来克服这一瓶颈。我们表明,先前针对特定类别的尝试无法推广到训练图像有限的稀有物种。我们通过引入蒙皮模型语义库(SBSM)来解决这一挑战,该模型通过将几何归纳先验与现成的自监督特征提取器隐式捕获的语义知识相结合,自动发现一小组基本动物形状。为了训练这样的模型,我们还贡献了一个新的不同动物物种的大规模数据集。在推理时,给定任何四足动物的单个图像,我们的模型会在几秒钟内以前馈方式重建铰接的 3D 网格。
概述
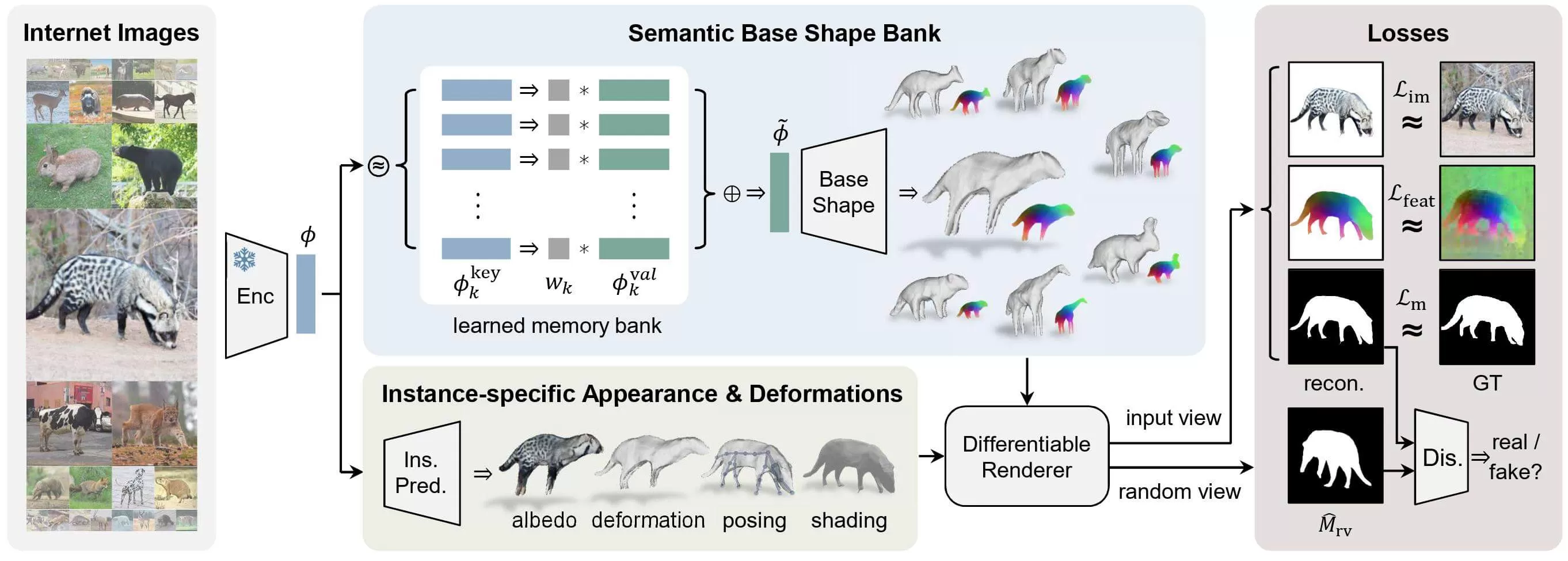
3D-Fauna仅使用来自互联网的单视图图像进行训练。给定每个输入图像,它首先使用预先训练的无监督图像编码器提取特征向量。然后用它来查询学习的记忆库,以生成标准姿势的基本形状和 DINO 特征字段。该模型还可以预测反照率、特定于实例的变形、关节姿势和光照,并通过 RGB、DINO 特征图和掩模上的图像重建损失以及掩模鉴别器损失进行训练,无需任何先前的形状模型或关键点注释。
单图像 3D 重建
给定任何四足动物的单个图像,没有任何类别信息,该模型会重建其铰接的 3D 形状和外观,可以从任意视点对其进行动画处理和重新渲染。
视频帧重建
我们还可以使用一种模型从视频帧中重建不同的动物。
形状插值
我们经过训练的形状库允许在来自不同输入图像的重建实例之间进行插值,这证明我们的形状空间是连续且平滑的。
自己尝试一下: 移动滑块以在插值视点(左)和固定视点(右)中插值形状。
基础形状银行抽样
我们还可以直接从经过训练的形状库中采样大量不同的形状。
书目词典
@article{li2024learning,
title = {Learning the 3D Fauna of the Web},
author = {Li, Zizhang and Litvak, Dor and Li, Ruining and Zhang, Yunzhi and Jakab, Tomas and Rupprecht, Christian and Wu, Shangzhe and Vedaldi, Andrea and Wu, Jiajun},
journal = {arXiv preprint arXiv:2401.02400},
year = {2024}
}致谢
我们非常感谢 Cristobal Eyzaguirre、Kyle Sargent、G Yunhao 的富有洞察力的讨论,以及 Chen Geng 的校对。这项工作得到了斯坦福以人为中心人工智能研究所 (HAI)、NSF RI #2211258、ONR MURI N00014-22-1-2740、三星全球研究外展 (GRO) 计划、亚马逊、谷歌和 EPSRC 的部分支持VisualAI EP/T028572/1。
相关工作
Dove:通过观看视频学习可变形的 3D 物体。国际JCV 2023。
MagicPony:在野外学习铰接式 3D 动物。CVPR 2023。
Farm3D:通过提取 2D 扩散来学习铰接式 3D 动物。3DV 2024。
Ponymation:从未标记的在线视频中学习 3D 动物动作。2023 年存档。
SAOR:单视图铰接对象重建。2023 年存档。
LASSIE:通过 3D 零件发现从稀疏图像集合中学习铰接形状。神经IPS 2022。
Hi-LASSIE:从稀疏图像集合中发现高保真铰接形状和骨架。CVPR 2023。
ARTIC3D:从嘈杂的 Web 图像集合中学习稳健的铰接 3D 形状。神经IPS 2023。
BANMo:从许多休闲视频构建可动画的 3D 神经模型。CVPR 2022。
RAC:从视频重建可动画类别。CVPR 2023。